3.4 Método do Gradiente
Ajude a manter o site livre, gratuito e sem propagandas. Colabore!
Começamos observando que se é uma matriz positiva definida4040endnote: 40 é simétrica e para todo ., temos que é solução de
| (3.440) |
se, e somente se, é solução do seguinte problema de minimização
| (3.441) |
De fato, sejam a solução de (3.440) e a solução de (3.441), então
| (3.442) | ||||
| (3.443) | ||||
| (3.444) |
O segundo termo é independente de e, como é positiva definida, temos
| (3.445) |
Logo, o mínimo de ocorre quando , i.e. .
A iteração do Método do Gradiente tem a forma
| (3.446) | ||||
para , onde é o tamanho do passo e é o vetor direção de busca.
Para escolhermos a direção , tomamos a fórmula de Taylor de em torno da aproximação
| (3.447) |
onde denota o gradiente de , i.e.
| (3.448) | ||||
| (3.449) |
De , segue que se
| (3.450) |
então , para suficientemente pequeno. Em particular, podemos escolher
| (3.451) |
se .
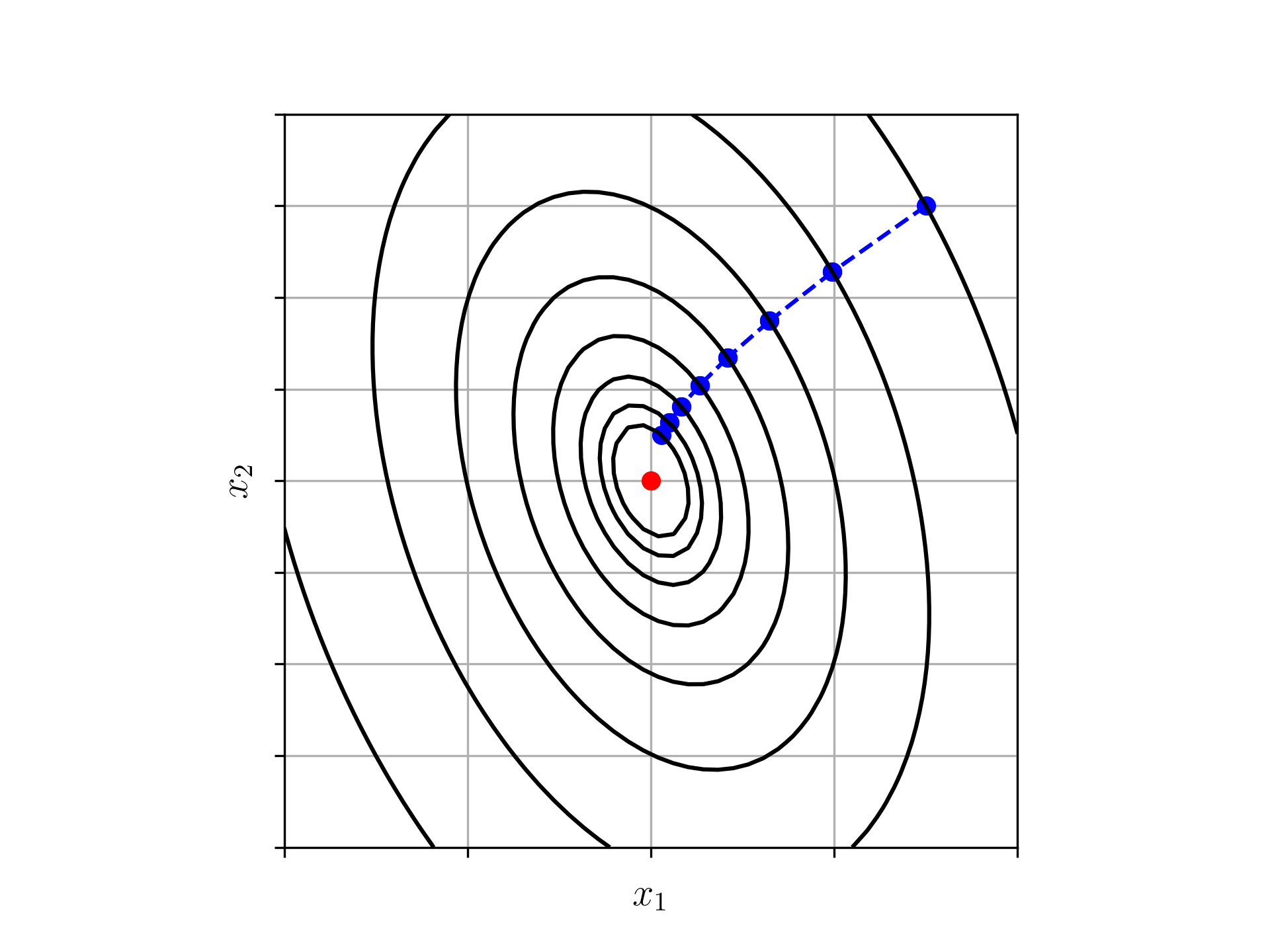
Do exposto acima, temos a iteração do Método do Gradiente
| (3.452) | ||||
com , onde é o resíduo
| (3.453) |
Exemplo 3.4.1.
Consideramos o sistema com
| (3.458) | ||||
| (3.463) |
Na Tabela 3.3 temos os resultados do emprego do método do gradiente com e com passo constante .
| k | ||
|---|---|---|
| 0 | ||
| 1 | ||
| 2 | ||
| 3 | ||
| 4 | ||
| 5 | ||
| 6 | ||
| 7 | ||
| 8 | ||
| 9 | ||
| 10 |
3.4.1 Escolha do Passo
Para a escolha do passo, podemos usar o Método da Pesquisa Linear. A ideia é escolher o passo tal que
| (3.464) |
Observando que é função apenas de , temos que seu mínimo ocorre em seu ponto crítico, i.e.
| (3.465) | |||
| (3.466) | |||
| (3.467) | |||
| (3.468) | |||
| (3.469) |
donde
| (3.470) |
Exemplo 3.4.2.
Consideramos o sistema com
| (3.475) | ||||
| (3.480) |
Na Tabela 3.4 temos os resultados do emprego do método do gradiente com e com passo escolhido conforme (3.470).
| k | |||
|---|---|---|---|
3.4.2 Exercícios
E. 3.4.1.
Considere o sistema linear com
| (3.485) | ||||
| (3.490) |
Por tentativa e erro, encontre um valor para tal que o Método do Gradiente converge para solução do sistema em menos de iterações. Use
| (3.491) |
como aproximação inicial e assuma o critério de parada
| (3.492) |
onde é o resíduo do sistema e .
Resposta.
,
E. 3.4.2.
Considere o sistema linear com
| (3.497) | ||||
| (3.502) |
Por tentativa e erro, encontre um valor para tal que o Método do Gradiente converge para solução do sistema em menos de iterações. Use
| (3.503) |
como aproximação inicial e assuma o critério de parada
| (3.504) |
onde é o resíduo do sistema e .
Resposta.
,
E. 3.4.3.
Considere o sistema linear dado no Exercício 3.4.1. Utilizando a mesma aproximação inicial e tolerância, aplique o Método do Gradiente com Pesquisa Linear. Quantas iterações são necessárias até a convergência e qual o valor médio de utilizado durante as iterações?
Resposta.
,
E. 3.4.4.
Considere o sistema linear dado no Exercício 3.4.2. Utilizando a mesma aproximação inicial e tolerância, aplique o Método do Gradiente com Pesquisa Linear. Quantas iterações são necessárias até a convergência e qual o valor médio de utilizado durante as iterações?
Resposta.
,
E. 3.4.5.
Considere o problema de Laplace
| (3.505) | ||||
| (3.506) |
A discretização pelo Método das Diferenças Finitas em uma malha uniforme , , , leva ao seguinte sistema linear
| (3.507) | |||
| (3.508) | |||
| (3.509) |
onde . Com , aplique o Método do Gradiente com Pesquisa Linear para computar a solução deste sistema quando . Quantas iterações são necessárias para obter-se a convergência do método com critério de convergência
| (3.510) |
onde, é o resíduo e .
Resposta.
Análise Numérica
E. 3.4.6.
Envie seu comentário
As informações preenchidas são enviadas por e-mail para o desenvolvedor do site e tratadas de forma privada. Consulte a Política de Uso de Dados para mais informações. Aproveito para agradecer a todas/os que de forma assídua ou esporádica contribuem enviando correções, sugestões e críticas!