3.3 Aplicação: Aproximação de Funções
Ajude a manter o site livre, gratuito e sem propagandas. Colabore!
Redes Perceptron Multicamadas (MLPs) são aproximadoras universais. Nesta seção, vamos aplicá-las na aproximação de funções uni- e bidimensionais.
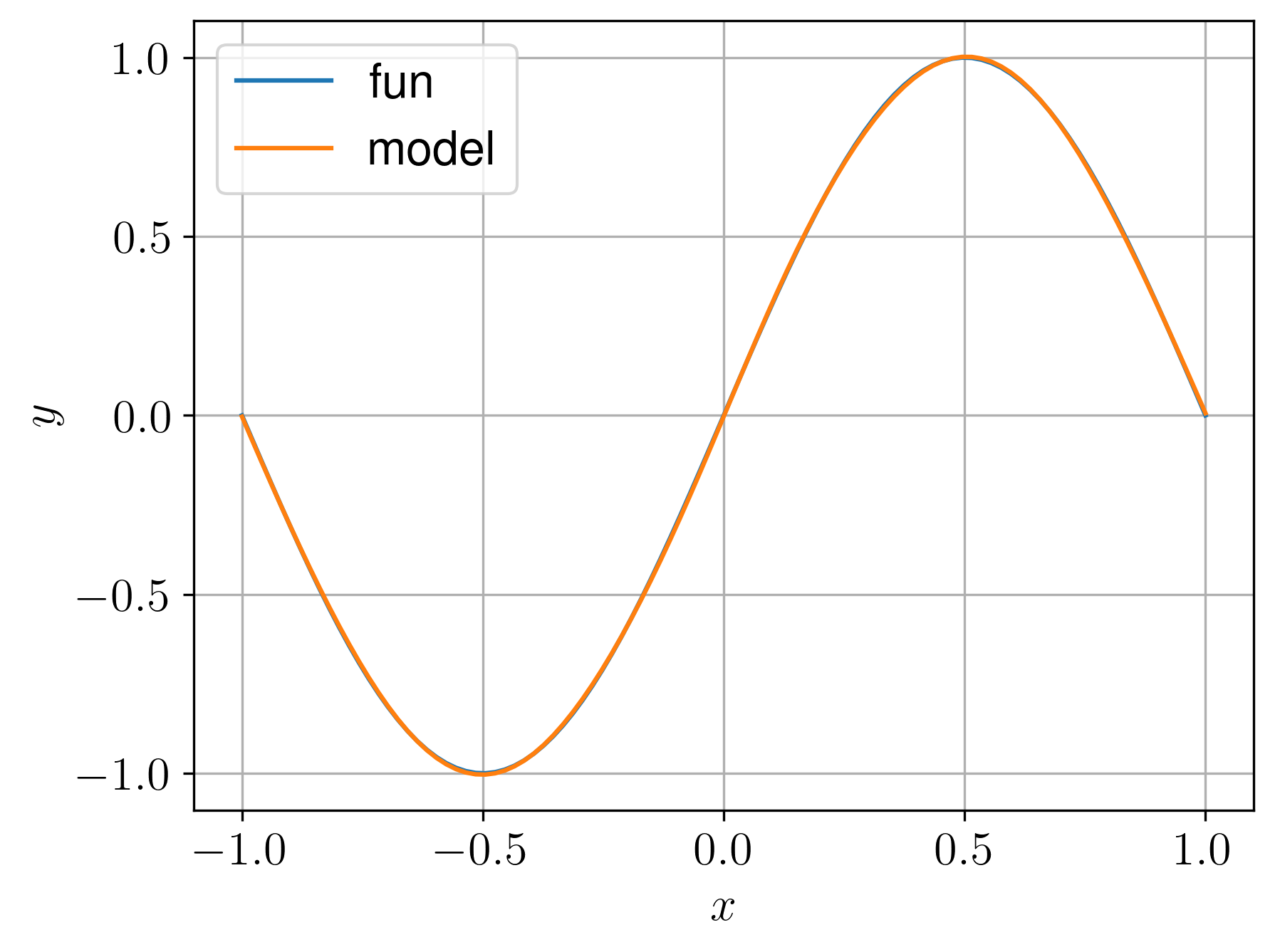
3.3.1 Função unidimensional
Vamos criar uma MLP para aproximar a função
| (3.14) |
para .
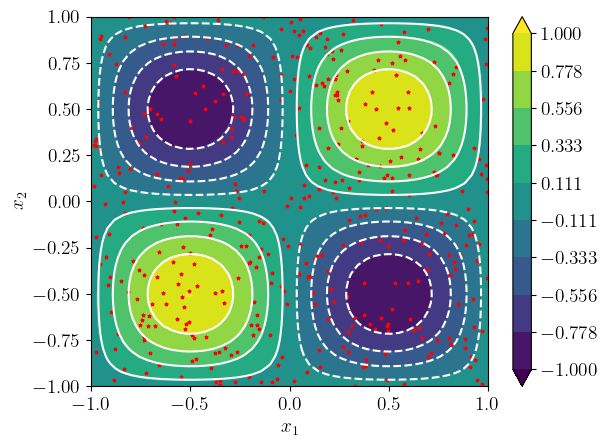
3.3.2 Função bidimensional
Vamos criar uma MLP para aproximar a função bidimensional
| (3.15) |
para .
Vamos usar uma arquitetura de rede (duas entradas, 3 camadas escondidas com neurônios e uma saída). Nas camadas escondidas, vamos usar a tangente hiperbólica como função de ativação.
Para o treinamento, vamos usar o erro médio quadrático como função erro
| (3.16) |
onde, a cada época, pontos randômicos88endnote: 8Em uma distribuição uniforme. são usados para gerar o conjunto de treinamento .
3.3.3 Exercícios
E. 3.3.1.
Crie uma MLP para aproximar a função gaussiana
| (3.17) |
para .
E. 3.3.2.
Crie uma MLP para aproximar a função para .
E. 3.3.3.
Crie uma MLP para aproximar a função para .
E. 3.3.4.
Crie uma MLP para aproximar a função gaussiana
| (3.18) |
para .
E. 3.3.5.
Crie uma MLP para aproximar a função para .
E. 3.3.6.
Crie uma MLP para aproximar a função para .
Envie seu comentário
As informações preenchidas são enviadas por e-mail para o desenvolvedor do site e tratadas de forma privada. Consulte a Política de Uso de Dados para mais informações. Aproveito para agradecer a todas/os que de forma assídua ou esporádica contribuem enviando correções, sugestões e críticas!