2.1 Olá, Mundo!
Ajude a manter o site livre, gratuito e sem propagandas. Colabore!
Em revisão

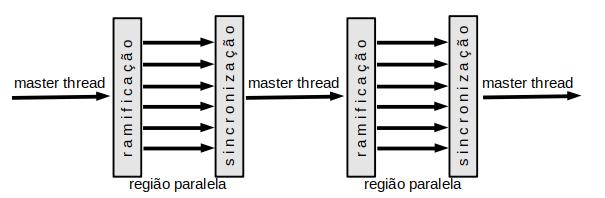
A computação paralela com MP inicia-se por uma instância de processamento master thread. Todas as instâncias de processamento disponíveis (threads) leem e escrevem variáveis compartilhadas. A ramificação (fork) do processo entre os threads disponíveis é feita por instrução explícita no início de uma região paralela do código. Ao final da região paralela, todos os threads sincronizam-se (join) e o processo segue apenas com o thread master. Veja a Figura 2.1.
Vamos escrever nosso primeiro código MP. O Código 1 inicia uma região paralela e cada instância de processamento escreve “Olá” e identifica-se.
Na linha 4, o API OpenMP é incluído no código. A região paralela vale dentro do escopo iniciado pela instrução
# pragma omp parallel
i.e., entre as linhas 9 e 15. Em paralelo, cada thread registra seu número de identificação na variável interira id, veja a linha 12. Na linha 14, escrevem a saudação, identificando-se.
Para compilar este código, digite no terminal
Ao compilar, um executável a.out será criado. Para executá-lo, basta digitar no terminal:
Ao executar, devemos ver a saída do terminal como algo parecido com
A saída irá depender do número de threads disponíveis na máquina e a ordem dos threads pode variar a cada execução. Execute o código várias vezes e analise as saídas!
Observação 2.1.1.
As variáveis declaradas dentro de uma região paralela são privadas de cada thread. As variáveis declaradas fora de uma região paralela são compartilhadas, sendo acessíveis por todos os threads.
2.1.1 Exercícios resolvidos
Em revisão
ER 2.1.1.
O número de instâncias de processamento pode ser alterado pela variável do sistema OMP_NUM_THREADS. Altere o número de threads para 2 e execute o Código 1.
Solução.
ER 2.1.2.
Escreva um código MP para ser executado com 2 threads. O master thread deve ler dois números em ponto flutuante. Então, em paralelo, um dos threads deve calcular a soma dos dois números e o outro thread deve calcular o produto.
Solução.
2.1.2 Exercícios
Em revisão
E. 2.1.1.
E. 2.1.2.
Defina um número de threads maior do que o disponível em sua máquina. Então, rode o Código 1 e analise a saída. O que você observa?
E. 2.1.3.
Faça um código MP para ser executado com 2 threads. O master thread deve ler dois números e não nulos em ponto flutuante. Em paralelo, um dos thread deve computar e o outro deve computar . Por fim, o master thread deve escrever .
E. 2.1.4.
Escreva um código MP para computar a multiplicação de uma matriz com um vetor de elementos. Inicialize todos os elementos com números randômicos em ponto flutuante. Ainda, o código deve ser escrito para um número arbitrário de instâncias de processamento. Por fim, compare o desempenho do código MP com uma versão serial do código.
E. 2.1.5.
Escreva um código MP para computar o produto de uma matriz com uma matriz de elementos, com . Inicialize todos os elementos com números randômicos em ponto flutuante. Ainda, o código deve ser escrito para um número arbitrário de instâncias de processamento. Por fim, compare o desempenho do código MP com uma versão serial do código.
Envie seu comentário
As informações preenchidas são enviadas por e-mail para o desenvolvedor do site e tratadas de forma privada. Consulte a Política de Uso de Dados para mais informações. Aproveito para agradecer a todas/os que de forma assídua ou esporádica contribuem enviando correções, sugestões e críticas!