Política de uso de dados
Ao navegar por este site, você concorda com a política de uso de dados.Política de uso de dados
Ao navegar por este site, você concorda com a política de uso de dados.Deep Learning para Equações Diferenciais Parciais
Ajude a manter o site livre, gratuito e sem propagandas. Colabore!
2.1 Unidade de processamento
A unidade básica de processamento (neurônio artificial) do tipo perceptron segue o esquema dado na Figura 2.1. Consiste na composição de uma função de ativação111Originalmente, o perceptron tem a função sinal como função de ativação. Por referência histórica, vamos adotar este nome mesmo para unidades de processamento com outras funções de ativação com a pré-ativação
| (2.1) | |||
| (2.2) |
onde, é o vetor de entrada, são of parâmetros da unidade, formados pelos pesos e o bias . Escolhida uma função de ativação, a saída do neurônio é computada por
| (2.3) | |||
| (2.4) |
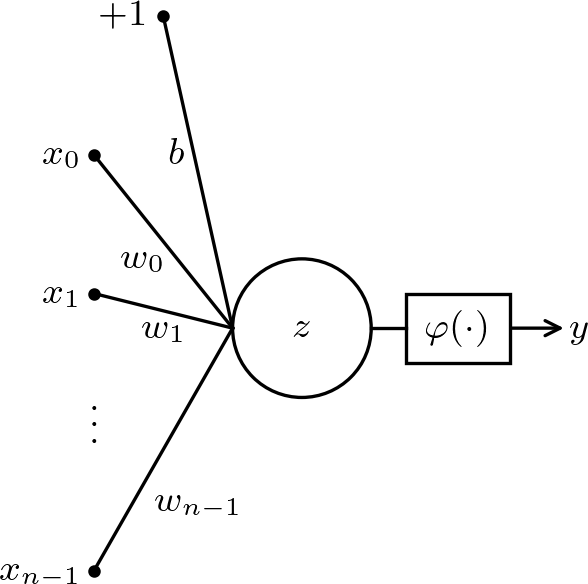
O treinamento (calibração) consiste em determinar os parâmetros de forma que o neurônio forneça as saídas esperadas com base em um critério predeterminado. O perceptron é um classificador linear, i.e. é capaz de classificar dados que sejam linearmente separáveis.
2.1.1 Um problema de classificação
Vamos desenvolver um perceptron que emule a operação booleana222George Boole, 1815 - 1864, matemático britânico. Fonte: Wikipédia: George Boole. (e-lógico). Mais especificamente, dados dois valores booleanos e (V, verdadeiro ou F, falso), esperamos que nosso neurônio forneça como saída o valor booleano . Lembremos a tabela verdade da operação :
| R | ||
|---|---|---|
| V | V | V |
| V | F | F |
| F | V | F |
| F | F | F |
Modelo
Nosso modelo será um perceptron com duas entradas e a função sinal
| (2.5) | |||
| (2.9) |
como função de ativação. Com isso, nosso modelo fornece a seguinte saída
| (2.10) | |||
| (2.11) |
onde são parâmetros a determinar. A ideia, aqui, é que o valor esteja associado ao valor lógico (falso) e o valor ao valor lógico (verdadeiro).
Pré-processamento
Precisamos pré-processar os dados do problema de forma a compatibilizá-los com o modelo. Assumindo que valor booleano (falso) seja associado a e que valor booleano (verdadeiro) a , temos os seguintes dados de treinamento para o nosso modelo de neurônio
| 1 | 1 | 1 |
|---|---|---|
| 1 | -1 | -1 |
| -1 | 1 | -1 |
| -1 | -1 | -1 |
Treinamento
Agora, nos falta treinar nosso neurônio para fornecer o valor de esperado para cada dada entrada . Isso consiste em um método para escolhermos os parâmetros que sejam adequados para esta tarefa. Vamos explorar mais sobre isso na sequência do texto, mas, aqui, vamos empregar uma análise geométrica para escolhermos os parâmetros .
Lembrando que nosso modelo é dado por
| (2.12) |
observamos que
| (2.13) |
corresponde à equação geral de uma reta no plano . Esta reta divide o plano em dois semiplanos
| (2.14) | |||
| (2.15) |
O primeiro está na direção do vetor normal à reta e o segundo no sentido oposto. Com isso, o problema de treinar nosso neurônio para o problema de classificação consiste em encontrar a reta
| (2.16) |
de forma que o ponto esteja no semiplano positivo e os demais pontos no semiplano negativo . Consultemos a Figura 2.2.
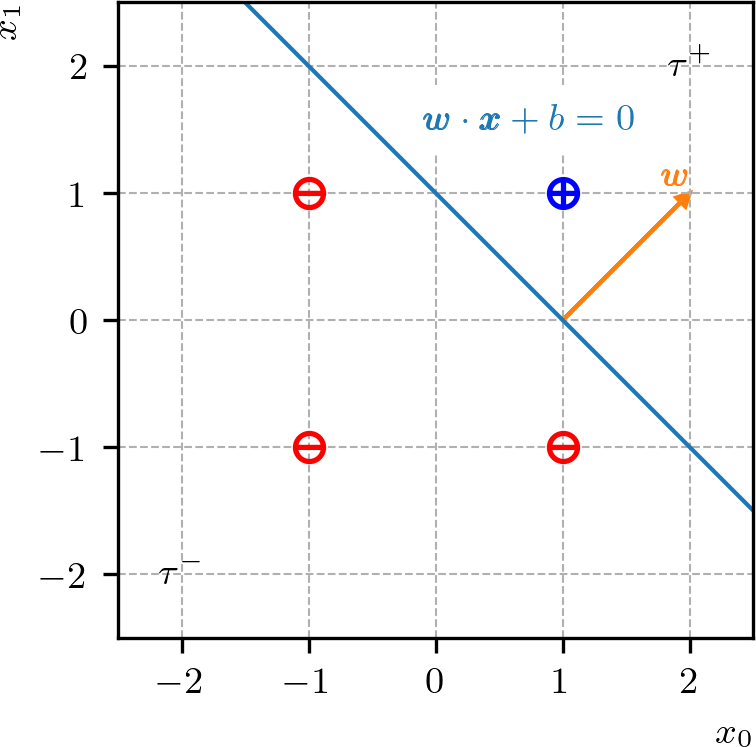
Com base nessa interpretação geométrica, podemos escolher os parâmetros do nosso modelo de neurônio. Por exemplo, podemos escolher
| (2.17) | |||
| (2.18) |
Com isso, nosso perceptron é
| (2.19) |
Verifique que o modelo fornece a saída esperada para cada dada entrada .
Implementação
O Código 1 é uma implementação deste modelo de neurônio. Verifique!
2.1.2 Algoritmo de treinamento: perceptron
O algoritmo de treinamento perceptron permite computar os parâmetros de um neurônio para fazer a classificação de dados linearmente separáveis. Trata-se de um algoritmo para o treinamento supervisionado de um modelo, i.e.. a calibração dos pesos é feita com base em um dado conjunto de amostras de treinamento.
Seja dado um conjunto de treinamento , onde é o número de amostras. O algoritmo consiste no seguinte:
-
1.
, .
-
2.
Para :
-
(a)
Para :
-
i.
Se :
-
A.
-
B.
-
A.
-
i.
-
(a)
onde, é um dado número de épocas. Usualmente, uma época consiste no número de vezes que todas as amostras serão utilizadas para realizar a correção dos pesos.
Para mostrarmos a convergência do algoritmo de treinamento perceptron, vamos simplificar a notação, assumindo . Com isso, um conjunto é linearmente separável, se existe tal que
| (2.20) |
para todas as amostras . Com isso, temos o seguinte resultado.
Teorema 2.1.1.(Perceptron)
Seja dado um conjunto de treinamento , onde é o número de amostras. Se existe tal que
| (2.21) |
e , para , então o algoritmo de treinamento perceptron converge em no máximo épocas.
Demonstração.
Assuma que iniciamos com e que na -ésima iteração de correção vamos computar os parâmetros . Seja o ângulo entre os vetores e , então
| (2.22) | |||
| (2.23) |
Sem perda de generalidade, suponhamos que a amostra seja a amostra que gera a correção na -ésima iteração, ou seja, . Com isso, temos
| (2.24) | |||
| (2.25) | |||
| (2.26) | |||
| (2.27) |
por indução matemática. Por outro lado, temos
| (2.28) | |||
| (2.29) | |||
| (2.30) | |||
| (2.31) |
novamente por indução matemática. Com isso, temos
| (2.32) |
e, portanto, . ∎
Aplicação
O Código 2 contém uma implementação do algoritmo de treinamento perceptron para o problema de classificação associado à operação lógica (e-lógico). Verifique!
2.1.3 Exercícios
E. 2.1.1.
Dado um perceptron com parâmetros e , esboce a reta de separação associada a este modelo e indique os semiplanos e . Então, classifique os seguintes pontos utilizando este modelo: , , e .
E. 2.1.2.
Crie um perceptron que emule a operação booleana do (ou-lógico).
| V | V | V |
| V | F | V |
| F | V | V |
| F | F | F |
Primeiramente, treine-o utilizando uma análise geométrica. Depois, implemente o algoritmo de treinamento perceptron para treinar os parâmetros do modelo.
E. 2.1.3.
Crie um perceptron que emule a operação booleana do (não-lógico).
| V | F |
| F | V |
Primeiramente, treine-o utilizando uma análise geométrica. Depois, implemente o algoritmo de treinamento perceptron para treinar os parâmetros do modelo.
E. 2.1.4.
Crie um perceptron que emule a operação booleana (nand-lógico).
| V | V | F |
| V | F | V |
| F | V | V |
| F | F | V |
Primeiramente, treine-o utilizando uma análise geométrica. Depois, implemente o algoritmo de treinamento perceptron para treinar os parâmetros do modelo.
E. 2.1.5.
Crie um perceptron que emule a operação booleana (nor-lógico).
| V | V | F |
| V | F | F |
| F | V | F |
| F | F | V |
Primeiramente, treine-o utilizando uma análise geométrica. Depois, implemente o algoritmo de treinamento perceptron para treinar os parâmetros do modelo.
E. 2.1.6.
Busque criar um perceptron que emule a operação lógica do xor.
| V | V | F |
| V | F | V |
| F | V | V |
| F | F | F |
É possível? Justifique sua resposta.
E. 2.1.7.
Crie um perceptron para classificar os seguintes dados
| 1.0 | 1.0 | 0.0 | 1 |
| 1.0 | 0.5 | 0.5 | 1 |
| 0.8 | 0.2 | 0.0 | 1 |
| 0.0 | 0.0 | 0.0 | -1 |
| 0.2 | 0.1 | 0.0 | -1 |
| -0.5 | 0.4 | 0.2 | -1 |
Treine-o utilizando o algoritmo de treinamento perceptron. Então, faça a interpretação geométrica do modelo encontrado.
E. 2.1.8.
No E.2.1.6, vimos que não é possível criar um perceptron para emular a operação lógica do xor. Assumindo que esteja associado ao valor e ao valor , podemos contornar esta limitação adicionando uma nova entrada ao modelo, que seja dada por . Verifique e explique como isso é possível. Implemente o modelo e treine-o utilizando o algoritmo de treinamento perceptron.
E. 2.1.9.
Dado um perceptron . Mostre que o valor absoluto de
| (2.34) |
é a distância do ponto à reta dada por . Ainda, mostre que o sinal de (2.34) está associado ao semiplano onde o ponto está localizado.
E. 2.1.10.
Considerando um conjunto de dados linearmente separáveis, verifique que o algoritmo de treinamento perceptron é convergente para uma escolha arbitrária de parâmetros iniciais. Faça a devida modificação no código do Código 2 e verifique a convergência do algoritmo para diferentes escolhas de parâmetros iniciais.
Envie seu comentário
Aproveito para agradecer a todas/os que de forma assídua ou esporádica contribuem enviando correções, sugestões e críticas!

Este texto é disponibilizado nos termos da Licença Creative Commons Atribuição-CompartilhaIgual 4.0 Internacional. Ícones e elementos gráficos podem estar sujeitos a condições adicionais.