Política de uso de dados
Ao navegar por este site, você concorda com a política de uso de dados.Política de uso de dados
Ao navegar por este site, você concorda com a política de uso de dados.Deep Learning para Equações Diferenciais Parciais
Ajude a manter o site livre, gratuito e sem propagandas. Colabore!
3.2 Aplicação: Aproximação de funções
Em revisão
Redes Perceptron Multicamadas (MLPs) são aproximadoras universais e vamos aplicá-las na aproximação de funções uni- e bidimensionais.
3.2.1 Teorema da aproximação universal
O teorema da aproximação universal pode ser visto como uma extensão do teorema de Weierstrass222Karl Theodor Wilhelm Weierstrass, 1815 - 1897, matemático alemão. Fonte: Wikipédia: Karl Weierstrass. para redes neurais. Ele afirma que uma MLP com uma camada oculta e uma função de ativação não linear pode aproximar qualquer função contínua em um espaço compacto, com precisão arbitrária, desde que a rede tenha um número suficiente de neurônios na camada oculta.
Teorema 3.2.1.(Aproximação universal)
Seja uma função contínua monotonicamente crescente e limitada. Sejam e uma dada função contínua de em . Então, para todo , existe um e um conjunto de constantes reais , e , , tais que a função
| (3.12) |
é uma aproximação de em no sentido de que
| (3.13) |
Demonstração.
Consulte [Cybenko1989a] para o caso de funções de ativação sigmoidal e [Hornik1991a] para o caso de funções de ativação mais gerais. ∎
O Teorema 3.2.1 é diretamente aplicável a uma rede MLP com uma camada escondida, tangente hiperbólica como função de ativação e uma camada de saída com função de ativação identidade. Ele garante que, para qualquer função contínua em um espaço compacto, existe uma MLP com essa arquitetura que pode aproximar com precisão arbitrária, desde que a camada escondida tenha um número suficiente de neurônios. A extensão do teorema para a aproximação de funções multivariadas é direta.
Redes MLP com função de ativação ReLU não se encaixam no Teorema 3.2.1. Entretanto, resultados teóricos sobre a aproximação de funções com tais redes também estão disponíveis. Consulte, por exemplo, [DeVore2021a].
O Teorema 3.2.1 é um resultado teórico importante, pois estabelece a capacidade de aproximação das MLPs. No entanto, ele não fornece uma maneira prática de determinar o número de neurônios necessários na camada escondida para alcançar uma determinada precisão, nem garante que o processo de treinamento da rede encontrará os pesos e biases adequados para realizar a aproximação desejada. Ainda, o teorema não estabelece que redes com apenas uma camada escondida sejam as melhores para a aproximação de funções, e sim que elas são suficientes. Na prática, redes com múltiplas camadas escondidas (redes profundas) podem ser mais eficientes para aproximar funções complexas.
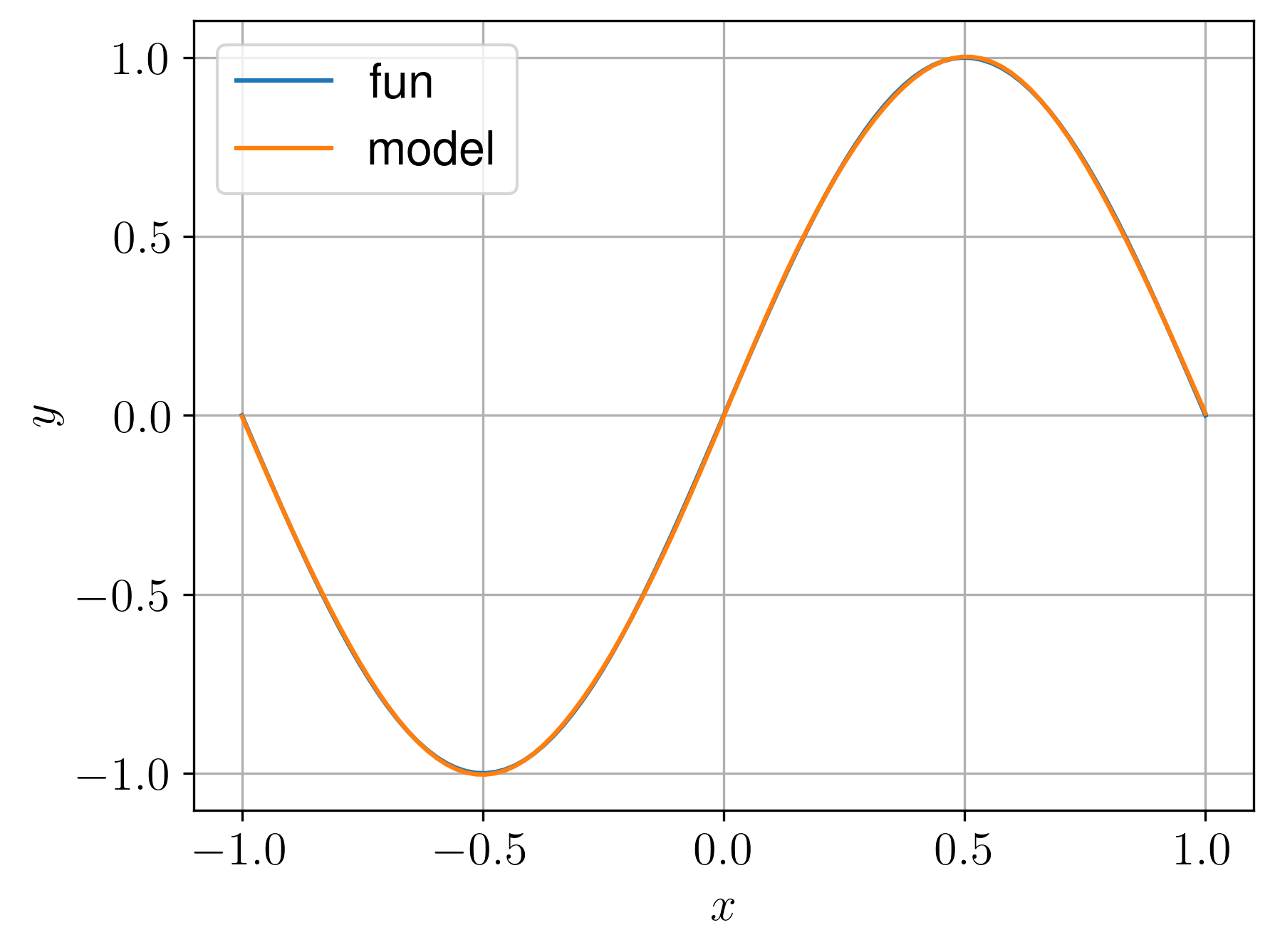
3.2.2 Função unidimensional
Vamos criar uma MLP para aproximar a função
| (3.14) |
para .
3.2.3 Função bidimensional
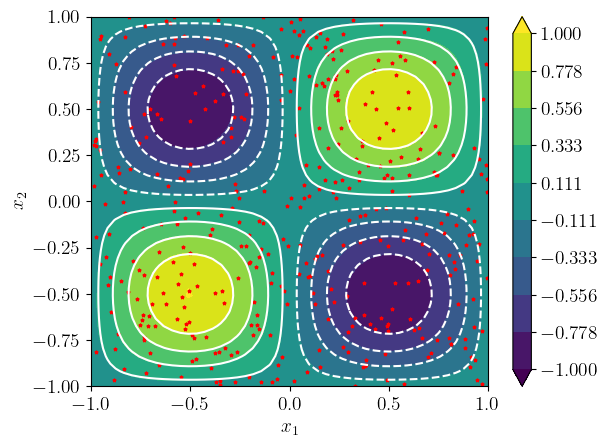
Vamos criar uma MLP para aproximar a função bidimensional
| (3.15) |
para .
Vamos usar uma arquitetura de rede (duas entradas, 3 camadas escondidas com neurônios e uma saída). Nas camadas escondidas, vamos usar a tangente hiperbólica como função de ativação.
Para o treinamento, vamos usar o erro médio quadrático como função erro
| (3.16) |
onde, a cada época, pontos randômicos333Em uma distribuição uniforme. são usados para gerar o conjunto de treinamento .
3.2.4 Exercícios
E. 3.2.1.
Crie uma MLP para aproximar a função gaussiana
| (3.17) |
para .
E. 3.2.2.
Crie uma MLP para aproximar a função para .
E. 3.2.3.
Crie uma MLP para aproximar a função para .
E. 3.2.4.
Crie uma MLP para aproximar a função gaussiana
| (3.18) |
para .
E. 3.2.5.
Crie uma MLP para aproximar a função para .
E. 3.2.6.
Crie uma MLP para aproximar a função para .
Envie seu comentário
Aproveito para agradecer a todas/os que de forma assídua ou esporádica contribuem enviando correções, sugestões e críticas!

Este texto é disponibilizado nos termos da Licença Creative Commons Atribuição-CompartilhaIgual 4.0 Internacional. Ícones e elementos gráficos podem estar sujeitos a condições adicionais.