Política de uso de dados
Ao navegar por este site, você concorda com a política de uso de dados.Política de uso de dados
Ao navegar por este site, você concorda com a política de uso de dados.Computação Paralela com C++
Ajude a manter o site livre, gratuito e sem propagandas. Colabore!
3.4 Reduções
Reduções são rotinas que reduzem um conjunto de dados em um conjunto menor. Um exemplo de redução é a rotina de calcular o traço de uma matriz quadrada. Aqui, vamos apresentar algumas soluções MPI de rotinas de redução.
A rotina MPI_Reduce, permite a redução de dados distribuídos em múltiplos processos. Consulte a Figura 3.5.
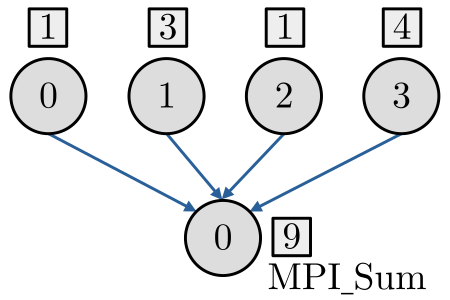
Sua sintaxe é a seguinte:
O argumento sendbuf aponta para o endereço de memória do dado a ser enviado por cada processo, enquanto que o argumento recvbuf aponta para o endereço de memória onde o resultado da redução será alocada no processo root. O argumento count é o número de dados enviados por cada processo e datatype é o tipo de dado a ser enviado (o qual deve ser igual ao tipo do resultado da redução). O argumento comm é o comunicador entre os processos envolvidos na redução. A operação de redução é definida pelo argumento op e pode ser um dos seguintes:
Exemplo 3.4.1.(Produto interno)
O seguinte Código 14 computa o produto interno entre dois vetores de números randômicos. Cada processo aloca um pedaço de cada vetor, computam o produto interno entre os pedaços e, então, o processo recebe o resultado da soma dos produtos internos computados em cada processo.
No caso de arrays de dados, a operação de redução é feita para cada componente. Consulte a Figura 3.6.
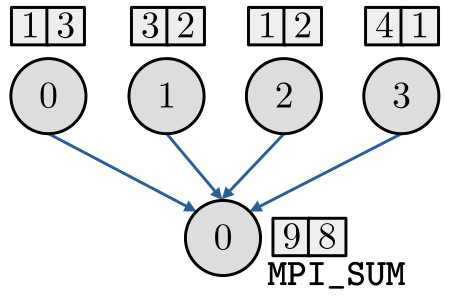
Observação 3.4.1.(MPI_Allreduce)
A rotina MPI_Allreduce executa uma redução de dados e o resultado é alocada em todos os processos. Sua sintaxe é similar a rotina MPI_Reduce, com exceção do argumento root, o qual não é necessário nessa rotina. Verifique!
Observação 3.4.2.(Reduções assíncronas)
As rotinas MPI_Ireduce e MPI_Iallreduce são versões assíncronas das rotinas MPI_Reduce e MPI_Allreduce, respectivamente.
3.4.1 Exercícios
E. 3.4.1.
E. 3.4.2.
E. 3.4.3.
Faça um código C++/Open MPI para computar a soma dos termos de um vetor de números randômicos, com , sendo o número de processos. Use a rotina MPI_Reduce e certifique-se de que cada processo aloque somente os dados necessários, otimizando o uso de memória computacional.
E. 3.4.4.
Faça um código C++/Open MPI para computar a norma do máximo de um vetor de números randômicos, com , sendo o número de processos. Use a rotina MPI_Reduce e certifique-se de que cada processo aloque somente os dados necessários, otimizando o uso de memória computacional.
E. 3.4.5.
Faça um código C++/Open MPI para computar a norma de um vetor de números randômicos, com , sendo o número de processos. Use a rotina MPI_Allreduce de forma que cada processo contenha a norma computada ao final do código.
Envie seu comentário
Aproveito para agradecer a todas/os que de forma assídua ou esporádica contribuem enviando correções, sugestões e críticas!

Este texto é disponibilizado nos termos da Licença Creative Commons Atribuição-CompartilhaIgual 4.0 Internacional. Ícones e elementos gráficos podem estar sujeitos a condições adicionais.