Política de uso de dados
Ao navegar por este site, você concorda com a política de uso de dados.Política de uso de dados
Ao navegar por este site, você concorda com a política de uso de dados.Computação Paralela com C++
Ajude a manter o site livre, gratuito e sem propagandas. Colabore!
3.3 Comunicações coletivas
Rotinas MPI de comunicações coletivas são aquelas que envolvem múltiplas instâncias de processamento. Elas são utilizadas para a troca de dados entre processos, onde um ou mais processos enviam dados para todos os demais processos ou recebem dados de todos os demais processos.
3.3.1 Barreira de sincronização
Podemos forçar a sincronização de todos os processos em um determinado ponto do código utilizando a rotina de sincronização MPI_Barrier. Sua sintaxe é a seguinte
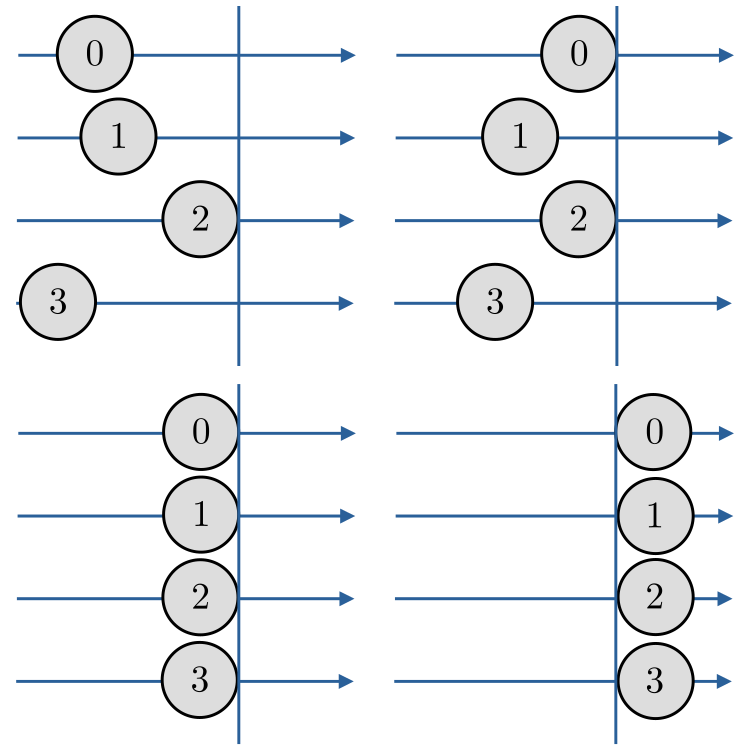
Quando um processo encontra esta rotina ele aguarda todos os demais processos. No momento em que todos os processo tiverem alcançados esta rotina, todos são liberados para seguirem com suas computações. Consulte a Figura 3.1.
Exemplo 3.3.1.
No Código 10, cada instância de processamento aguarda randomicamente até 3 segundos para alcançar a rotina de sincronização MPI_Barrier (na linha 15). Em seguida, elas são liberadas juntas. Estude o código.
3.3.2 Transmissão coletiva
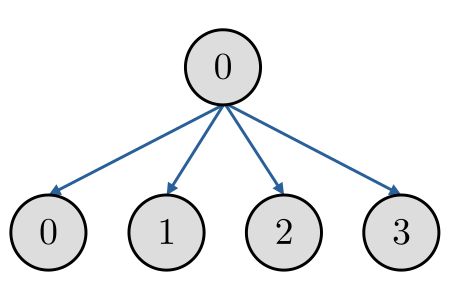
A rotina de transmissão de dados MPI_Bcast permite o envio de dados de um processo para todos os processos (incluindo a si próprio). Consulte a Figura 3.2.
Sua sintaxe é a seguinte:
O primeiro argumento buffer aponta para o endereço da memória do dado a ser transmitido. O argumento count é a quantidade de dados sucessivos que serão transmitidos. O tipo de dado é informado no argumento datatype. Por fim, root é o identificador rank do processo que está transmitindo e comm é o comunicador.
Exemplo 3.3.2.
No seguinte Código 11, o processo 0 inicializa a variável de ponto flutuante e, então, transmite ela para todos os demais processos. Por fim, cada processo imprime no terminal o valor alocado na sua variável .
3.3.3 Distribuição coletiva de dados
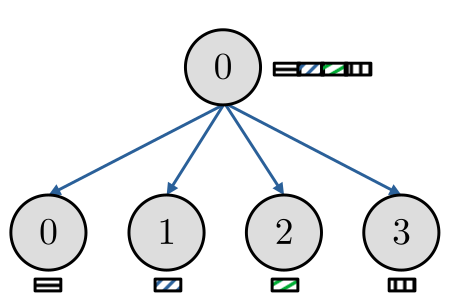
A rotina MPI_Scatter permite que um processo faça a distribuição uniforme de pedaços sequenciais de um array de dados para todos os processos. Consulte a Figura 3.3.
Sua sintaxe é a seguinte:
O primeiro argumento sendbuf aponta para o endereço de memória da array de dados a ser distribuída. O argumento sendcount é o tamanho do pedaço e sendtype é o tipo de dado a ser transmitido. Os argumentos recvbuf, recvcount e recvtype se referem ao ponteiro para o local de memória onde o dado recebido será alocado, o tamanho do pedaço a ser recebido e o tipo de dado, respectivamente. Por fim, o argumento root identifica o processo de origem da distribuição dos dados e comm é o comunicador.
Exemplo 3.3.3.
No Código scatter.cc abaixo, o processo 0 aloca o vetor
| (3.5) |
distribui pedaços sequenciais do vetor para cada processo no comunicador MPI_COMM_WORLD e, então, cada processo imprime o pedaço recebido.
Observação 3.3.1.(MPI_Scatter)
A MPI_Scatter distribuí apenas pedaços de tamanhos iguais de um array. Para a distribuição de pedaços de tamanhos diferentes entre os processos, pode-se usar a rotina MPI_Scatterv.
3.3.4 Recebimento coletivo de dados distribuídos
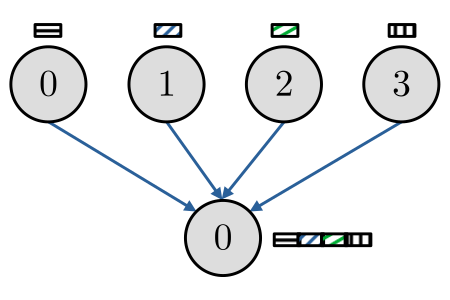
A rotina MPI_Gather permite que um processo colete simultaneamente dados que estão distribuídos entre os demais processos. Consulte a Figura 3.4.
Sua sintaxe é a seguinte:
Sua sintaxe é parecida com a da rotina MPI_Scatter (consulte a Subseção anterior). Veja lá! Aqui, root é o identificador rank do processo receptor.
Exemplo 3.3.4.
No Código 13, cada processo aloca um vetor
| (3.6) |
então, o processo 0 recebe estes vetores alocando-os em um único vetor
| (3.7) |
onde é o número de processos inicializados.
Observação 3.3.2.(MPI_Gather)
Para recebimento de pedaços distribuídos e de tamanhos diferentes, pode-se usar a rotina MPI_Gatherv.
Observação 3.3.3.(MPI_Allgather)
A rotina MPI_Allgather nos permite juntar os pedaços de dados distribuídos e ter uma cópia completa em todos os processos. Sua sintaxe é a seguinte
Observemos que esta rotina não contém o argumento root, pois, neste caso, todos os processos são receptores.
3.3.5 Exercícios
E. 3.3.1.
Faça um código MPI para computar a média aritmética simples de números randômicos em ponto flutuante.
E. 3.3.2.
Faça um código MPI para computar o produto interno de dois vetores de elementos randômicos em ponto flutuante.
E. 3.3.3.
Faça um código MPI para computar a norma de um vetor de elementos randômicos em ponto flutuante.
E. 3.3.4.
E. 3.3.5.
Faça uma implementação MPI do método de Jacobi para computar a solução de um sistema . Inicialize e com números randômicos em ponto flutuante.
Envie seu comentário
Aproveito para agradecer a todas/os que de forma assídua ou esporádica contribuem enviando correções, sugestões e críticas!

Este texto é disponibilizado nos termos da Licença Creative Commons Atribuição-CompartilhaIgual 4.0 Internacional. Ícones e elementos gráficos podem estar sujeitos a condições adicionais.
Computação Paralela com C++
Ajude a manter o site livre, gratuito e sem propagandas. Colabore!
3.3 Comunicações coletivas
Rotinas MPI de comunicações coletivas são aquelas que envolvem múltiplas instâncias de processamento. Elas são utilizadas para a troca de dados entre processos, onde um ou mais processos enviam dados para todos os demais processos ou recebem dados de todos os demais processos.
3.3.1 Barreira de sincronização
Podemos forçar a sincronização de todos os processos em um determinado ponto do código utilizando a rotina de sincronização MPI_Barrier. Sua sintaxe é a seguinte
Quando um processo encontra esta rotina ele aguarda todos os demais processos. No momento em que todos os processo tiverem alcançados esta rotina, todos são liberados para seguirem com suas computações. Consulte a Figura 3.1.
Exemplo 3.3.1.
No Código 10, cada instância de processamento aguarda randomicamente até 3 segundos para alcançar a rotina de sincronização MPI_Barrier (na linha 15). Em seguida, elas são liberadas juntas. Estude o código.
3.3.2 Transmissão coletiva
A rotina de transmissão de dados MPI_Bcast permite o envio de dados de um processo para todos os processos (incluindo a si próprio). Consulte a Figura 3.2.
Sua sintaxe é a seguinte:
O primeiro argumento buffer aponta para o endereço da memória do dado a ser transmitido. O argumento count é a quantidade de dados sucessivos que serão transmitidos. O tipo de dado é informado no argumento datatype. Por fim, root é o identificador rank do processo que está transmitindo e comm é o comunicador.
Exemplo 3.3.2.
No seguinte Código 11, o processo 0 inicializa a variável de ponto flutuante e, então, transmite ela para todos os demais processos. Por fim, cada processo imprime no terminal o valor alocado na sua variável .
3.3.3 Distribuição coletiva de dados
A rotina MPI_Scatter permite que um processo faça a distribuição uniforme de pedaços sequenciais de um array de dados para todos os processos. Consulte a Figura 3.3.
Sua sintaxe é a seguinte:
O primeiro argumento sendbuf aponta para o endereço de memória da array de dados a ser distribuída. O argumento sendcount é o tamanho do pedaço e sendtype é o tipo de dado a ser transmitido. Os argumentos recvbuf, recvcount e recvtype se referem ao ponteiro para o local de memória onde o dado recebido será alocado, o tamanho do pedaço a ser recebido e o tipo de dado, respectivamente. Por fim, o argumento root identifica o processo de origem da distribuição dos dados e comm é o comunicador.
Exemplo 3.3.3.
No Código scatter.cc abaixo, o processo 0 aloca o vetor
| (3.5) |
distribui pedaços sequenciais do vetor para cada processo no comunicador MPI_COMM_WORLD e, então, cada processo imprime o pedaço recebido.
Observação 3.3.1.(MPI_Scatter)
A MPI_Scatter distribuí apenas pedaços de tamanhos iguais de um array. Para a distribuição de pedaços de tamanhos diferentes entre os processos, pode-se usar a rotina MPI_Scatterv.
3.3.4 Recebimento coletivo de dados distribuídos
A rotina MPI_Gather permite que um processo colete simultaneamente dados que estão distribuídos entre os demais processos. Consulte a Figura 3.4.
Sua sintaxe é a seguinte:
Sua sintaxe é parecida com a da rotina MPI_Scatter (consulte a Subseção anterior). Veja lá! Aqui, root é o identificador rank do processo receptor.
Exemplo 3.3.4.
No Código 13, cada processo aloca um vetor
| (3.6) |
então, o processo 0 recebe estes vetores alocando-os em um único vetor
| (3.7) |
onde é o número de processos inicializados.
Observação 3.3.2.(MPI_Gather)
Para recebimento de pedaços distribuídos e de tamanhos diferentes, pode-se usar a rotina MPI_Gatherv.
Observação 3.3.3.(MPI_Allgather)
A rotina MPI_Allgather nos permite juntar os pedaços de dados distribuídos e ter uma cópia completa em todos os processos. Sua sintaxe é a seguinte
Observemos que esta rotina não contém o argumento root, pois, neste caso, todos os processos são receptores.
3.3.5 Exercícios
E. 3.3.1.
Faça um código MPI para computar a média aritmética simples de números randômicos em ponto flutuante.
E. 3.3.2.
Faça um código MPI para computar o produto interno de dois vetores de elementos randômicos em ponto flutuante.
E. 3.3.3.
Faça um código MPI para computar a norma de um vetor de elementos randômicos em ponto flutuante.
E. 3.3.4.
E. 3.3.5.
Faça uma implementação MPI do método de Jacobi para computar a solução de um sistema . Inicialize e com números randômicos em ponto flutuante.
Envie seu comentário
Aproveito para agradecer a todas/os que de forma assídua ou esporádica contribuem enviando correções, sugestões e críticas!
Este texto é disponibilizado nos termos da Licença Creative Commons Atribuição-CompartilhaIgual 4.0 Internacional. Ícones e elementos gráficos podem estar sujeitos a condições adicionais.